计算机系统基础综合实践 PA2
x86 指令系统
PA2的任务是实现基本x86指令,i386手册——INTEL 80386
PROGRAMMER’S REFERENCE MANUAL 1986
(mit.edu) 里全面地列出了所有指令的细节。
前言
此次实验目的是为了能够了解汇编语言中指令的各处细节,掌握IA-32指令格式,并且对NEMU平台中的指令周期了解地更加全面。PA2会开始涉及到一些计算机系统基础的知识。
实验内容
阶段 1: 编写 helper 函数, 在 NEMU 中运行第一个 C 程序——mov-c.c
阶段 2: 实现更多的指令,并通过测试
阶段 3:完善简易调试器
阶段 4:实现 loader
最后阶段: 实现黑客运行时劫持实验(选做)
开始实验
x86指令格式
指令格式
x86指令的格式由这几个部分组成。除了Opcode一定出现以外,其他都是可选的。当Opcode前缀为66时,表示16位操作数,否则表示32位操作数。
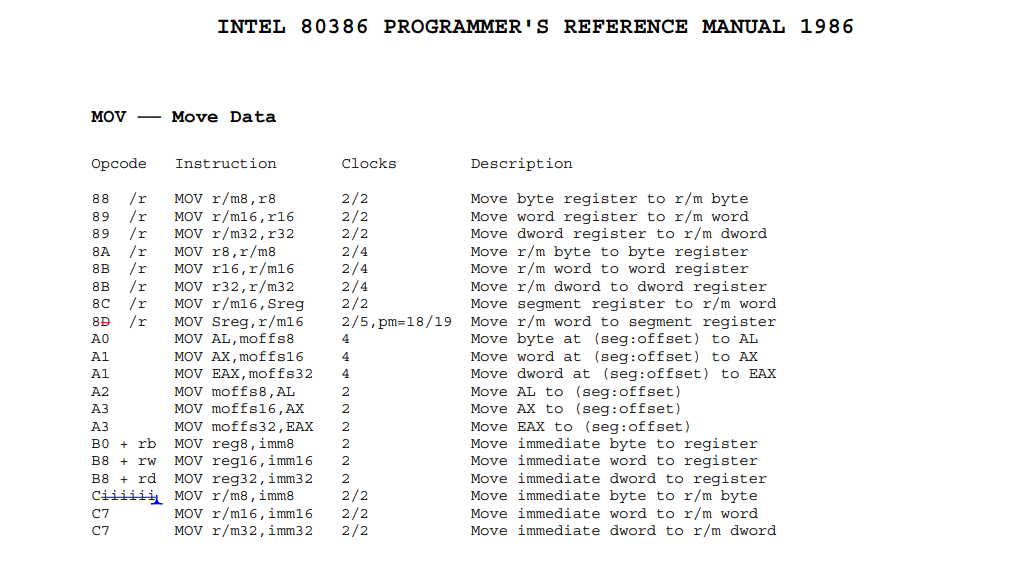
MOV
img
i386手册里的都是Intel格式,objdump的默认格式为AT&T。这里以mov为例,功能描述里r/m表示为寄存器或内存,r/m后面的数值表示为多少位的寄存器,Opcode为89的有两种形式,而前面提到Opcode前缀就是用来区分16位和32位的,例如开始如果出现66
8B,则应该被解释成MOV
r16,r/m16。Sreg表示段寄存器,moffs表示段内偏移,段的概念会以后提到。+rb
+rw
+rd则表示8位,16位,32位寄存器,可以通过按数值加法来确定唯一的寄存器。
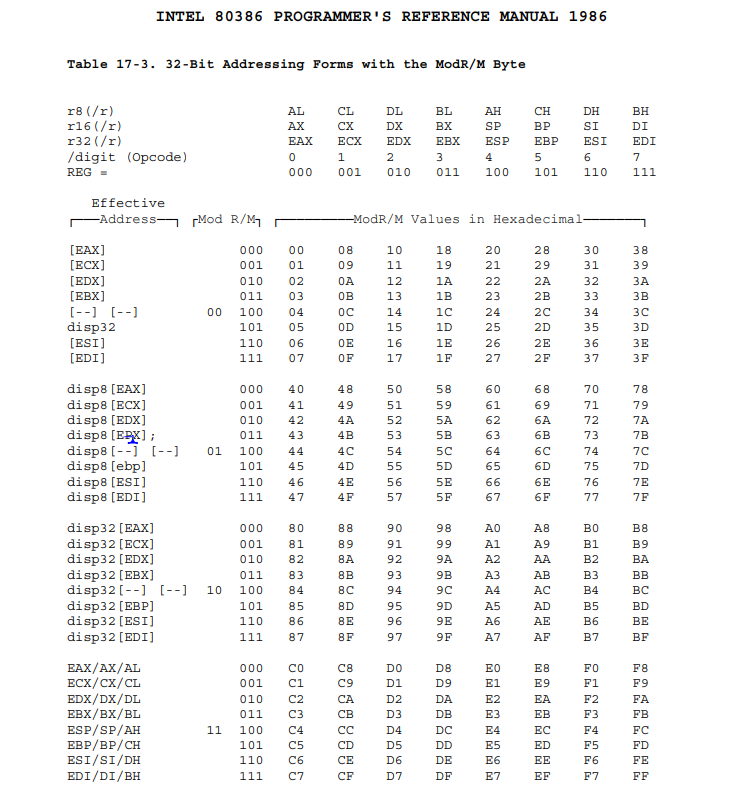
ModR/M Table
pa2-1.png
ModR/M域分成三个部分,Mod为2位,所以Mod可以指定4种寻址方式,每一种选择里还对应着不同的选择,这些便是由R/M来决定,而R/M为3位,所以又可以选择8种寻址方式。所以Mod
+
R/M可以组合成32种寻址方式,其中为8种为寄存器寻址,另24种为存储器寻址。Reg/Opcode则可以表示成8个寄存器或者对于Opcode的一个补充。以上为32位ModR/M的表。
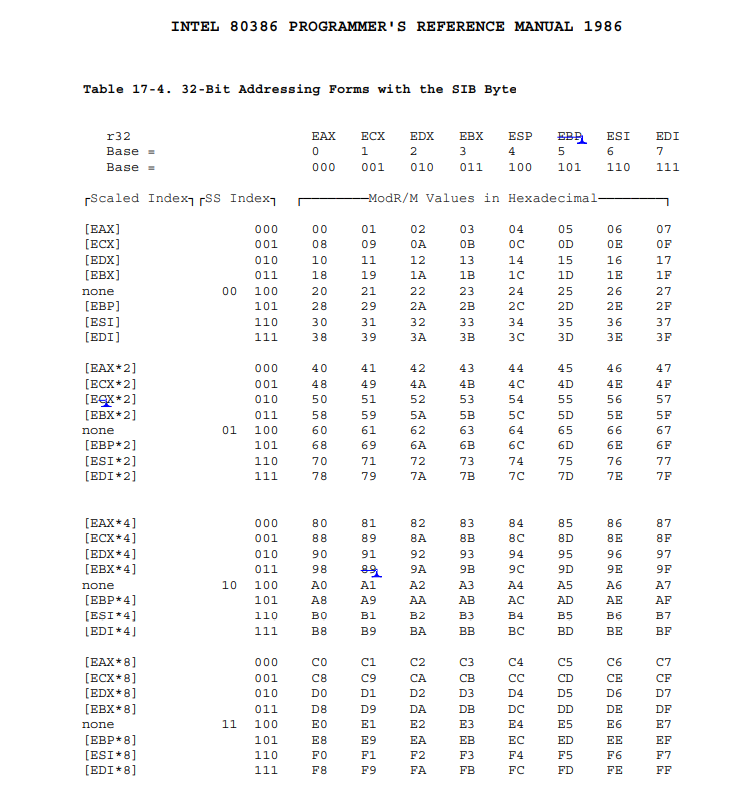
SIB Table
image.png
R/M代表的是寄存器还是内存,是由Mod决定的,当mod =
3时,r/m表示的是寄存器操作,否则为内存操作。ModR/M表中画横线的部分表示要使用到索引寻址,这时候便会使用到SIB,SIB由三个部分组成,Base代表基址寄存器,Index表示变址寄存器,SS表示比例系数。举个例子,例如
mov [ebx + eax * 2], ecx
,ebx为Base,eax为Index,2为SS。以上为SIB的表。
至于Displacement和Immediate则分别表示成偏移数和立即数,这两个都是按照小端序排列。例如,mov
0x1a2b[ebx + eax * 2], ecx ,其中的0x1a2b表示Displacement。
这里的图都是还未被修正过的,图中画蓝线的部分是错误的,需要自行对照勘误表
补充
由于一个字节为8位,最多只能表示成256个形式,一旦指令形式的数目大于256时,这时候就需要用到转移码的概念或者利用Reg/Opcode中的Opcode来补充指令。
x86中分别有两字节转移码和三字节转移码,当Opcode前一个字节为0x0f或者前两个字节为0x0f和0x38的时候,表示需要再读入一个字节来确定唯一的指令形式。
当Reg/Opcode域被当作Opcode来解释的时候,这些指令会被划分为不同的指令组,在同一个指令组的指令则需要通过Reg/Opcode域中的Opcode来唯一确定。
必做任务 1:运行用户程序
mov-c
首先需要查找i386 手册中指令的相关篇幅,通过指令的Opcode决定指令的具体形式。之后根据实验给出的代码框架,实现指令需要创建三个文件,分别为xxx-template.h、xxx.c、xxx.h。最后必须在nemu/src/cpu/exec/all-instar.h 包含所创建的指令头文件,并且在nemu/src/cpu/exec/exec.c 中依照Opcode在正确的位置添加与之相对应的指令。PA2代码框架中所定义的宏极为重要,在实现指令时可以省去很多重复的步骤,需要仔细阅读实验指导书并且理解。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 (nemu) c invalid opcode(eip = 0x001012c5): e8 c6 fe ff ff e8 d1 fe ... There are two cases which will trigger this unexpected exception: 1. The instruction at eip = 0x001012c5 is not implemented. 2. Something is implemented incorrectly. Find this eip value(0x001012c5) in the disassembling result to distinguish which case it is. If it is the first case , see _ ____ ___ __ __ __ _ (_)___ \ / _ \ / / | \/ | | | _ __) | (_) |/ /_ | \ / | __ _ _ __ _ _ __ _| | | ||__ < > _ <| '_ \ | |\/| |/ _` | ' _ \| | | |/ _` | | | |___) | (_) | (_) | | | | | (_| | | | | |_| | (_| | | |_|____/ \___/ \___/ |_| |_|\__,_|_| |_|\__,_|\__,_|_| for more details.If it is the second case , remember: * The machine is always right! * Every line of untested code is always wrong! nemu: nemu/src/cpu/exec/special/special.c:24: inv: Assertion `0' failed. Makefile:63: recipe for target ' run' fail
修改NEMU根目录下Make
File中的用户程序后,执行NEMU会发现报错,错误原因是还没有实现0xe8为首字节的指令。下面会给出两个实现指令的过程,剩余指令就不给出了。
实现call指令
nemu/src/cpu/exec/control/call-template.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include "cpu/exec/template-start.h" #define instr call make_helper(concat(call_i_, SUFFIX)) { int len = concat(decode_i_, SUFFIX)(eip + 1 ); reg_l(R_ESP) -= DATA_BYTE; MEM_W(reg_l(R_ESP), cpu.eip + len + 1 ); cpu.eip += (DATA_TYPE_S)op_src->val; print_asm("call: 0x%x" , cpu.eip + len + 1 ); return len + 1 ; } make_helper(concat(call_rm_, SUFFIX)) { int len = concat(decode_rm_, SUFFIX)(eip + 1 ); reg_l(R_ESP) -= DATA_BYTE; MEM_W(reg_l(R_ESP), cpu.eip + len + 1 ); cpu.eip = (DATA_TYPE_S)op_src->val - len - 1 ; print_asm("call: %s" , op_src->str); return len + 1 ; } #include "cpu/exec/template-end.h"
编写call指令模板文件。call指令可以大致分成三个步骤。
esp = esp - DATA_BYTE,栈腾出位置。
[esp] = 返回地址 ,把返回地址压入栈中。
eip跳转到函数地址。
这里涉及了对指针ESP、帧指针EBP、栈函数调用栈、栈帧等各方面的理解。栈指针ESP永远指向系统栈中最上面一个栈帧的栈顶,而帧指针EBP则永远指向系统战中最上面一个栈帧的栈底,这两个指针的作用主要是用来保存(或恢复)堆栈。后续有个选做任务也是和这个的类似。
nemu/src/cpu/exec/control/call.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include "cpu/exec/helper.h" #define DATA_BYTE 1 #include "call-template.h" #undef DATA_BYTE #define DATA_BYTE 2 #include "call-template.h" #undef DATA_BYTE #define DATA_BYTE 4 #include "call-template.h" #undef DATA_BYTE make_helper_v(call_i) make_helper_v(call_rm)
编写call指令实例化文件。
nemu/src/cpu/exec/control/call.h
1 2 3 4 5 #include "cpu/exec/helper.h" make_helper(call_i_v); make_helper(call_rm_v);
编写call指令头文件。
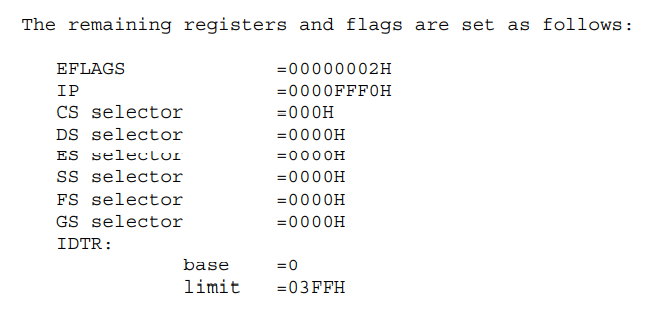
EFLAGS寄存器
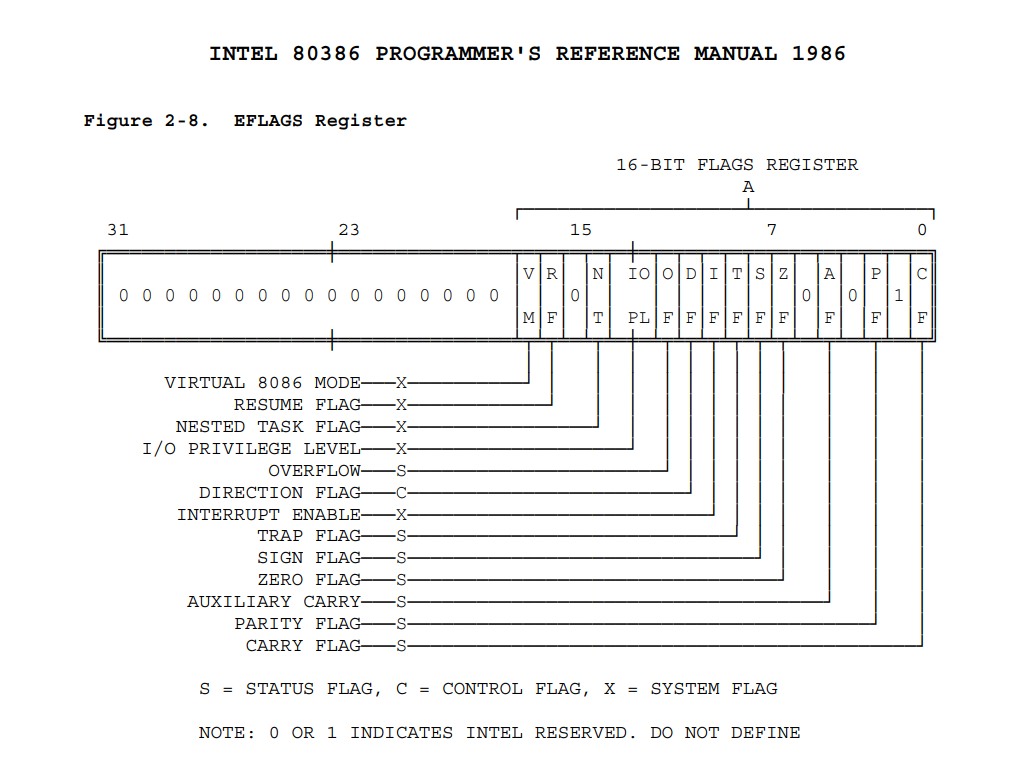
EFLAGS寄存器结构
image.png
一些指令执行的时候会更新EFLAGSZ中某些标志位的值,例如test指令,这是一个32位寄存器。第1、3、5、15以及22到31位会被保留,其余的标志位有些可以被特殊的指令直接被修改,但是并没有任何一条指令可以查看或者修改整个寄存器。
CF:进位标志,如果运算的结果最高位产生了进位或借位,其值为1,否则为0。
PF:奇偶标志,计算运算结果里1的奇偶性,偶数为1,否则为0。
AF:辅助进位标志,取运算结果最后四位,最后四位向前有进位或借位,其值为1,否则为0。
ZF:零标志,相关指令结束后判断是否为0,结果为0,其值为1,否则为0。
SF:符号标志,相关质量结束后判断正负,结果为负,其值为1,否则为0。
TF:单步标志,当其值为1时,表示处理器每次只执行一条指令。
IF:中断使能标志,表示能否响应外部中断,若能响应外部中断,其值为1,否则为0。
DF:方向标志,当DF为1,ESI、EDI自动递减,否则自动递增。
OF:溢出标志,反映有符号数运算结果是否溢出,如果溢出,其值为1,否则为0。
img
代码框架已经为我们实现好了EFLAGS寄存器的结构,但是需要为EFLAGS寄存器初始化。i386手册第十章有给出EFLAGS寄存器的初始值。
实现test指令
nemu/src/monitor/monitor.c
1 2 3 4 5 void restart () { cpu.eflags.val = 0x00000002 ; }
将EFLAGS寄存器初始为0x00000002。
nemu/src/cpu/exec/logic/test-template.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include "cpu/exec/template-start.h" #define instr test static void do_execute () { DATA_TYPE ret = op_dest -> val & op_src -> val; cpu.eflags.SF = ret >> ((DATA_BYTE << 3 ) - 1 ); cpu.eflags.ZF = !ret; cpu.eflags.CF = 0 ; cpu.eflags.OF = 0 ; ret ^= ret >> 4 ; ret ^= ret >> 2 ; ret ^= ret >> 1 ; ret &= 1 ; cpu.eflags.PF = !ret; DATA_TYPE result = op_dest -> val & op_src -> val; update_eflags_pf_zf_sf((DATA_TYPE_S)result); cpu.eflags.CF = cpu.eflags.OF = 0 ; print_asm_template1(); } make_instr_helper(i2a) make_instr_helper(i2rm) make_instr_helper(r2rm) #include "cpu/exec/template-end.h"
编写test指令模板文件。由于test指令执行需要更新标志位,这里可以手动为EFLAGS寄存器的各个标志位赋值,也可以利用代码框架提供的函数update_eflags_pf_zf_sf()更新pf、zf、sf这三个标志位。
nemu/src/cpu/exec/logic/test.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include "cpu/exec/helper.h" #define DATA_BYTE 1 #include "test-template.h" #undef DATA_BYTE #define DATA_BYTE 2 #include "test-template.h" #undef DATA_BYTE #define DATA_BYTE 4 #include "test-template.h" #undef DATA_BYTE make_helper_v(test_i2a) make_helper_v(test_i2rm) make_helper_v(test_r2rm)
编写test指令实例化文件。
nemu/src/cpu/exec/logic/test.h
1 2 3 4 5 6 7 8 9 10 11 12 #ifndef __TEST_H__ #define __TEST_H__ make_helper(test_i2a_b); make_helper(test_i2rm_b); make_helper(test_r2rm_b); make_helper(test_i2a_v); make_helper(test_i2rm_v); make_helper(test_r2rm_v); #endif
编写test指令头文件。
输出结果
1 2 3 4 5 6 7 objcopy -S -O binary obj/kernel/kernel entry obj/nemu/nemu obj/testcase/mov-c Welcome to NEMU! The executable is obj/testcase/mov-c. For help , type "help" (nemu) c .nemu: HIT GOOD TRAP at eip = 0xc0101325
成功运行用户程序mov-c。
必做任务 2:实现更多指令
此次任务需要通过所有testcase下目录的程序,除了这五个hello-inline-asm、
hello、integral、quadratic-eq、print-FLOAT。这个可以说是整个PA代码量最大的一次任务,需要反复查阅i386手册。
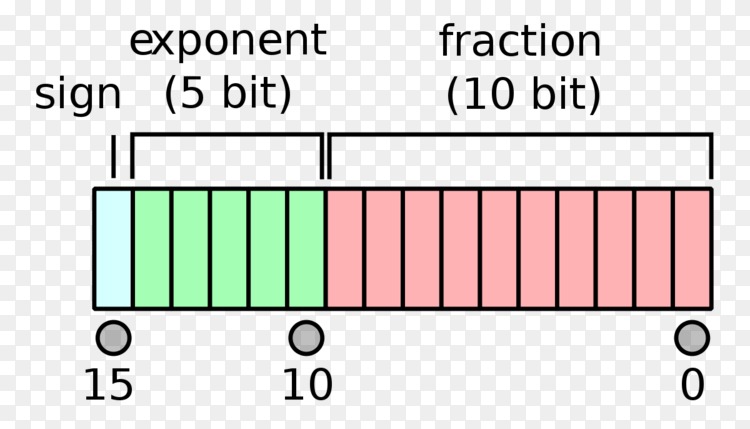
浮点数
单精度浮点数结构
img
浮点数遵循着IEEE 754标准。
浮点数详解(IEEE
754标准) · Issue #27 · fang0jun/Blog · GitHub
定点化浮点数
x86架构上引进了协处理器x87架构,所以就可以处理浮点数运算相关的指令。但是NEMU中不实现类似x87架构的指令系统,所以引进了一个概念,”浮点数定点化”,是通过32位整数来模拟浮点数,就是为了让NEMU实现类似浮点数的机制,称作定点数。
定点数结构
image.png
sign为1位,负数,其值为1,否则为0。
integer为15位,表示实数中整数的部分,如果整数部分超过15位则会发生溢出。
fraction为16位,表示实数中小数的部分,只保留小数16位。
实数转为定点数的时候需要乘2^16,相反亦是如此。例如实数1.5,1.5 * 2^16
= 98304 ,也就是0x18000。
image.png
0x18000 / 2^16 = 1.5
,这样就完成了实数和定点数相互转换的过程。实数转定点数会失去表数范围和精度,但是这样的做法可以换取速度,只不过这里的例子恰好没有让实数失去精度。
必做任务3:实现 binary
scaling
此次任务需要通过integral和quadratic-eq这两个程序,这两个程序涉及到了浮点数的使用。NEMU中可以识别浮点数,但是却没有与之相对应的浮点数运算指令。而我们需要做的是把浮点数转为定点数,并且实现基本运算。
nemu/lib-common/FLOAT.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #ifndef __FLOAT_H__ #define __FLOAT_H__ #include "trap.h" typedef int FLOAT;static inline int F2int (FLOAT a) { a &= 0xffff0000 ; return a >> 16 ; } static inline FLOAT int2F (int a) { return a << 16 ; } static inline FLOAT F_mul_int (FLOAT a, int b) { return a * b; } static inline FLOAT F_div_int (FLOAT a, int b) { return a / b; }
定点数转整数只要取出低四位然后右移16位就可以了,右移16位就是等于/
2^16,整数转定点数直接 * 2^16。定点数和整数的乘法和除法不用 *
216,因为当中的定点数的结果已经是*
2 16了,再乘的话就等于乘上两个2的16次方了。
nemu/lib-common/FLOAT/FLOAT.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include "FLOAT.h" FLOAT F_mul_F (FLOAT a, FLOAT b) { long long c = (long long )a * (long long )b; return (FLOAT)(c >> 16 ); } FLOAT F_div_F (FLOAT a, FLOAT b) { FLOAT p, q; asm volatile ("idiv %2" : "=a" (p), "=d" (q) : "r" (b), "a" (a << 16 ), "d" (a >> 16 )) ; return p; } FLOAT f2F (float a) { int b = *(int *)&a; int sign = b >> 31 ; int exp = (b >> 23 ) & 0xff ; FLOAT c = b & 0x7fffff ; if (exp != 0 ) { c += 1 << 23 ; } exp -= 150 ; if (exp < -16 ) { c >>= -16 - exp ; } if (exp > -16 ) { c <<= exp + 16 ; } return sign == 0 ? c : -c; } FLOAT Fabs (FLOAT a) { FLOAT b; if (a > 0 ){ b = a; } else { b = -a; } return b; }
两个定点数相乘要用long
long的类型,绝对值的话直接把小于0的数乘上个负数。剩余有两点需要注意,一个是浮点数如何转换成定点数,需要了解浮点数 具体的结构,另一个则是运用内联汇编。
gcc
内联汇编格式以及详解_坚持的力量-CSDN博客
之后根据实验指导书中需要修改的地方都修改后,便可运行integral和quadratic-eq这两个程序。
必做任务
4:为表达式求值添加变量的支持
这里涉及到了一些ELF文件里的一些细节,在下面有一个任务也是要去理解elf文件。
nemu/src/monitor/debug/elf.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 uint32_t getValue (char * str,bool * success) { int i; for (i = 0 ; i < nr_symtab_entry; i++){ if ((symtab[i].st_info & 0xf ) == STT_OBJECT || (symtab[i].st_info & 0xf ) == STT_FUNC){ if (strcmp (strtab + symtab[i].st_name, str) == 0 ){ return symtab[i].st_value; } } } *success = false ; return 0 ; } char * getFuncName (swaddr_t eip) { int i; for (i = 0 ; i < nr_symtab_entry; i ++) { if ((symtab[i].st_info & 0xf ) == STT_FUNC ){ if (eip >= symtab[i].st_value && eip <= symtab[i].st_value + symtab[i].st_size) { return strtab + symtab[i].st_name; } } } return 0 ; }
STT_OBJECT代表符号的类型是一个数据对象,例如变量、数组、指针,STT_FUNC则代表符号的类型是一个函数。符号的类型在低四位,所以这边要与上一个0xf用来对比地址低4位。字符串表(st_name)加上符号偏移量(strtab)等于符号所在地址。在符号表中取出相应函数的地址和函数名(选做任务),之后在nemu/src/monitor/debug/expr.c 添加相应的规则后,便可在表达式中使用变量了。
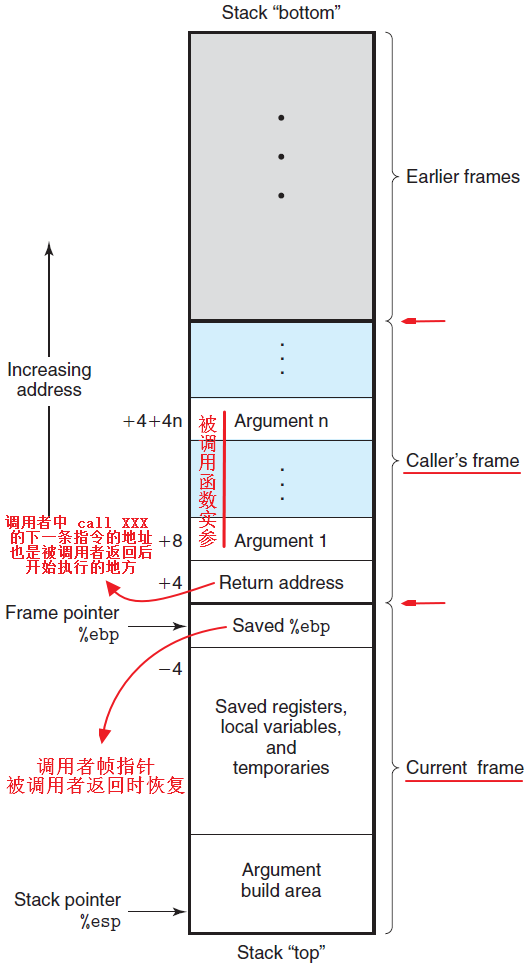
栈帧链
栈帧链
img
栈帧链大致的概念就是,在若干次函数调用时会在堆栈中形成栈帧。在调用函数之前,调用函数的当前栈帧会保存自己的信息,此时ESP指向当前栈帧底部、EBP指向当前栈帧顶部。而调用函数之后,首先会把被调用函数的参数和调用函数的返回地址压入栈,并且被调用函数现在有了一个自己的栈帧,此时EBP和ESP分别指向被调用函数的栈帧底部和栈帧顶部。
选做任务 1:打印栈帧链
这里需要理解栈帧和函数过程调用。
nemu/src/monitor/debug/ui.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 typedef struct { swaddr_t prev_ebp; swaddr_t ret_addr; }PartOfStackFrame ; char * getFuncName (int eip) ;static int cmd_bt (char *args) { PartOfStackFrame frame; frame.ret_addr = cpu.eip; swaddr_t temp_ebp = cpu.ebp; int count = 0 ; while (temp_ebp){ printf ("#%d\t0x%x\t%s\t0x%x\t0x%x\t0x%x\t0x%x\n" , count++, frame.ret_addr, getFuncName(cpu.eip), swaddr_read(temp_ebp + 8 , 4 ), swaddr_read(temp_ebp + 12 , 4 ), swaddr_read(temp_ebp + 16 , 4 ), swaddr_read(temp_ebp + 20 , 4 )); frame.prev_ebp = swaddr_read(temp_ebp, 4 ); frame.ret_addr = swaddr_read(temp_ebp + 4 , 4 ); temp_ebp = frame.prev_ebp; } return 0 ;
只需要打印出函数名、返回地址以及前四个参数。利用一个变量temp_ebp记录当前ebp的值,需要记录当前ebp和上一个栈帧链的返回地址(存在当前ebp上面,参数存在当前ebp上上面),最后更新temp_ebp,此时temp_ebp指向当前栈帧底部,ret_addr指向栈帧顶部,当ebp不为空则表示当前还有栈帧。
ELF文件
ELF文件提供了两个视角,分别为面向链接的section 视角和面向执行的segment 视角。里面很多细节,直接上链接。
ELF文件解析(一):Segment和Section
- JollyWing - 博客园 (cnblogs.com)
ELF文件解析(二):ELF
header详解 - JollyWing - 博客园 (cnblogs.com)
ELF格式探析之三:sections
- JollyWing - 博客园 (cnblogs.com)
必做任务 5:实现 loader
kernel/src/elf/elf.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 uint32_t loader () { const uint32_t elf_magic = 0x464c457f ; uint32_t *p_magic = (void *)buf; nemu_assert(*p_magic == elf_magic); int i; ph = (void *)(buf + elf->e_phoff); for (i = 0 ; i < elf->e_phnum; i++) { if (ph->p_type == PT_LOAD) { uint32_t pa = ph->p_vaddr; ramdisk_read((void *)pa,ph->p_offset,ph->p_filesz); memset ((void *)pa+ph->p_filesz,0 ,ph->p_memsz-ph->p_filesz); ph ++; }
首先需要正确定义ELF的Magic
Word用来识别文件是否为ELF格式,这里用了框架代码中给出的函数ramdisk_read()用于读出ramdisk里的内容,然后把segment的代码正确加载。最后依照实验指导书中指示需要修改的部分后修改,即可完成此次任务,算是为PA3开一个头。
选做任务2:
实现黑客运行时劫持实验
有时间再做,好像是有点类似csapp的lab。